


Glueのスケジュールではなくて、S3の終了ファイルをトリガにクローラを実行したい場合のために作りました。
S3データをパーティションに分けている場合、クローラを実行してパーティションを読み込ます必要があります。
Lambda関数
import sys
import boto3
import json
import logging
import os
import datetime
import calendar
from base64 import b64decode
from urllib.request import Request, urlopen
from urllib.error import URLError, HTTPError
logger = logging.getLogger()
logger.setLevel(logging.INFO)
glue = boto3.client('glue')
def lambda_handler(event, context):
if 'eventSource' in event['Records'][0]:
if event['Records'][0]['eventSource'] == 'aws:s3':
reason = event['Records'][0]['s3']
bucket = event['Records'][0]['s3']['bucket']['name']
key = event['Records'][0]['s3']['object']['key']
if ('_SUCCESS' in key):
logger.info("bucket: " + str(bucket) + " key: " + str(key))
response = glue.start_crawler(Name='glue クローラ名')
S3イベントの設定

S3バケットのプロパティを選びます。
見逃しやすいですが、プロパティの下のほうにあるイベントを選びます。
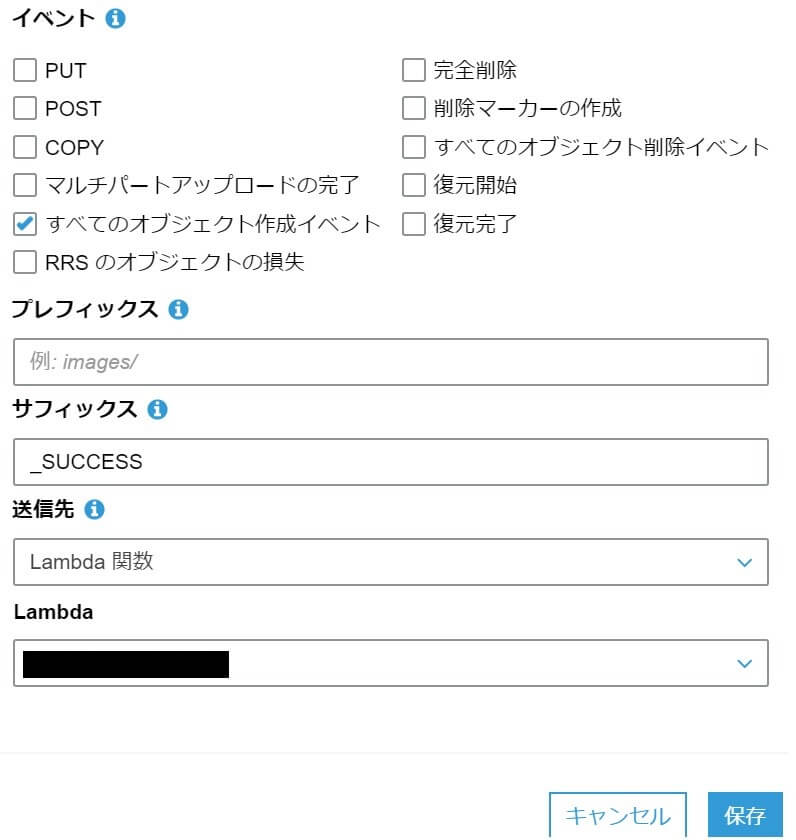
イベントの「すべてのオブジェクト作成イベント」をチェックします。
送信先を「Lambda関数」にして
Lambdaに上で作った関数名を指定します。
